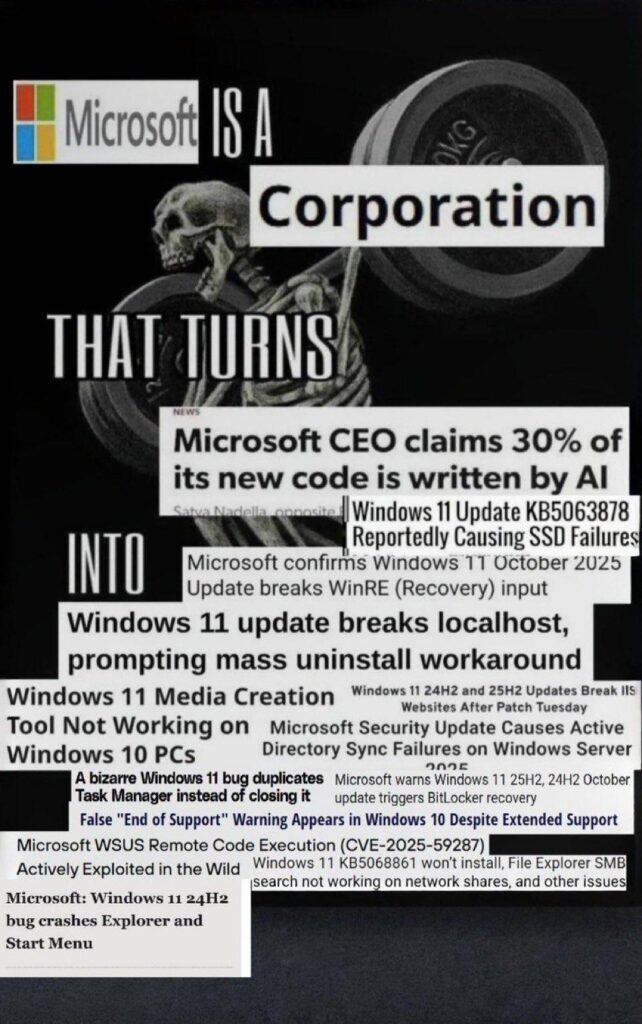
Over the recent weekend, roon (@tszzl), a prominent voice among tech circles on Twitter and an employee at OpenAI, tweeted the following:
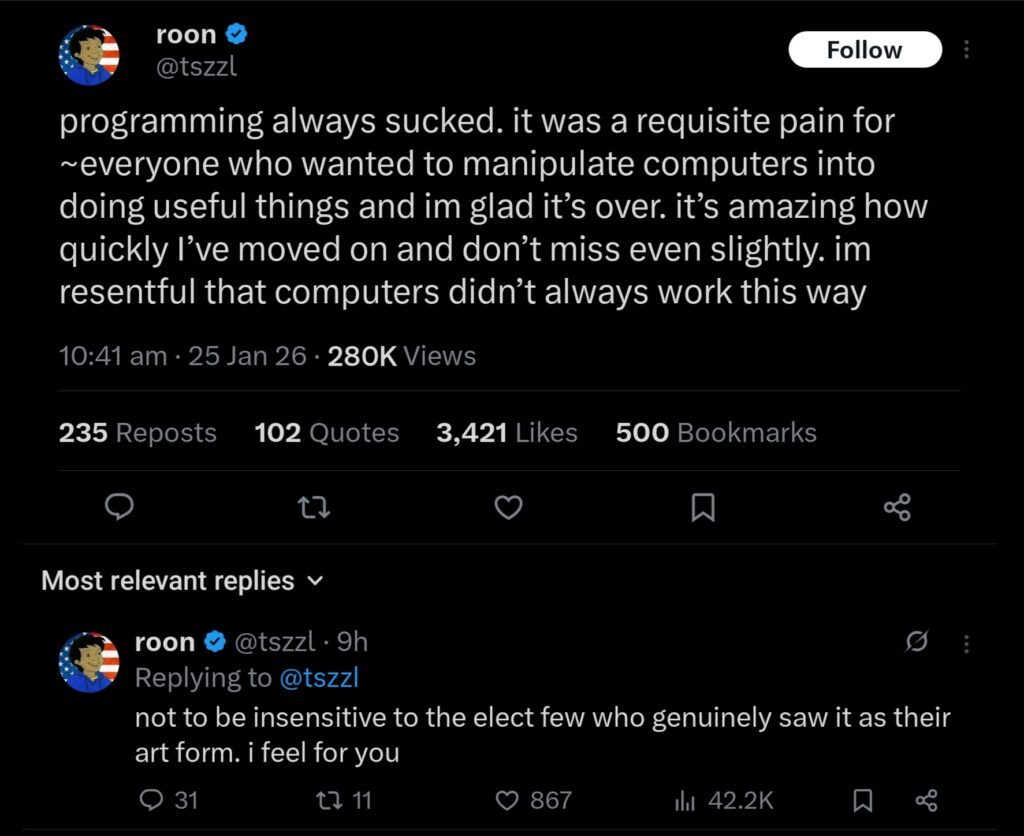
Like many in the Silicon Valley cultural sphere, roon has openly embraced ‘vibe-coding’ – using LLMs for programming. As this tweet makes clear however, this is not simply because of the alleged productivity gains. This is an explicit rejection of the manual act of programming, something he perceives as tiresome and frustrating. He’s not alone in this sentiment:
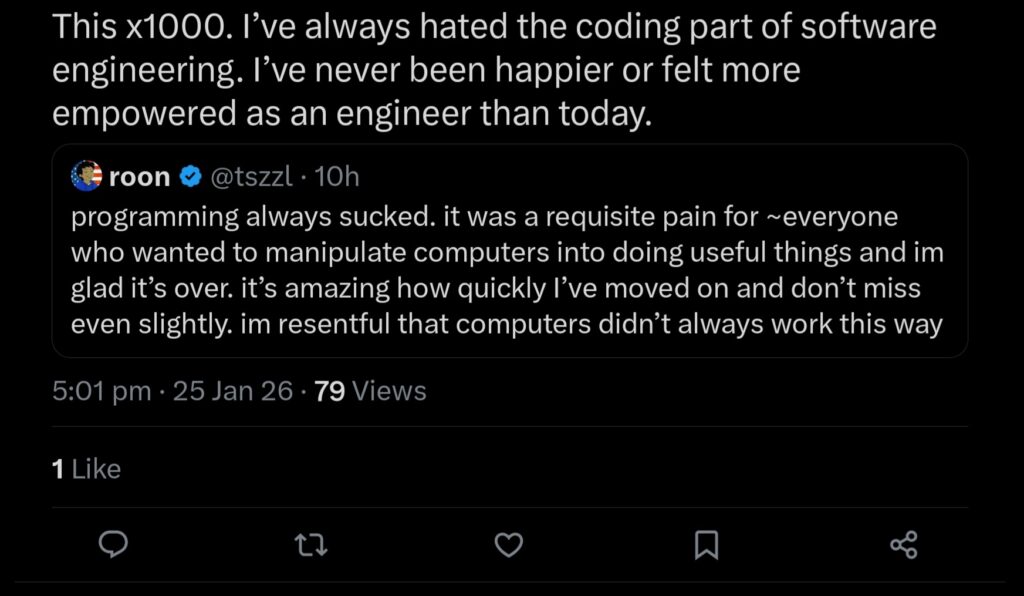
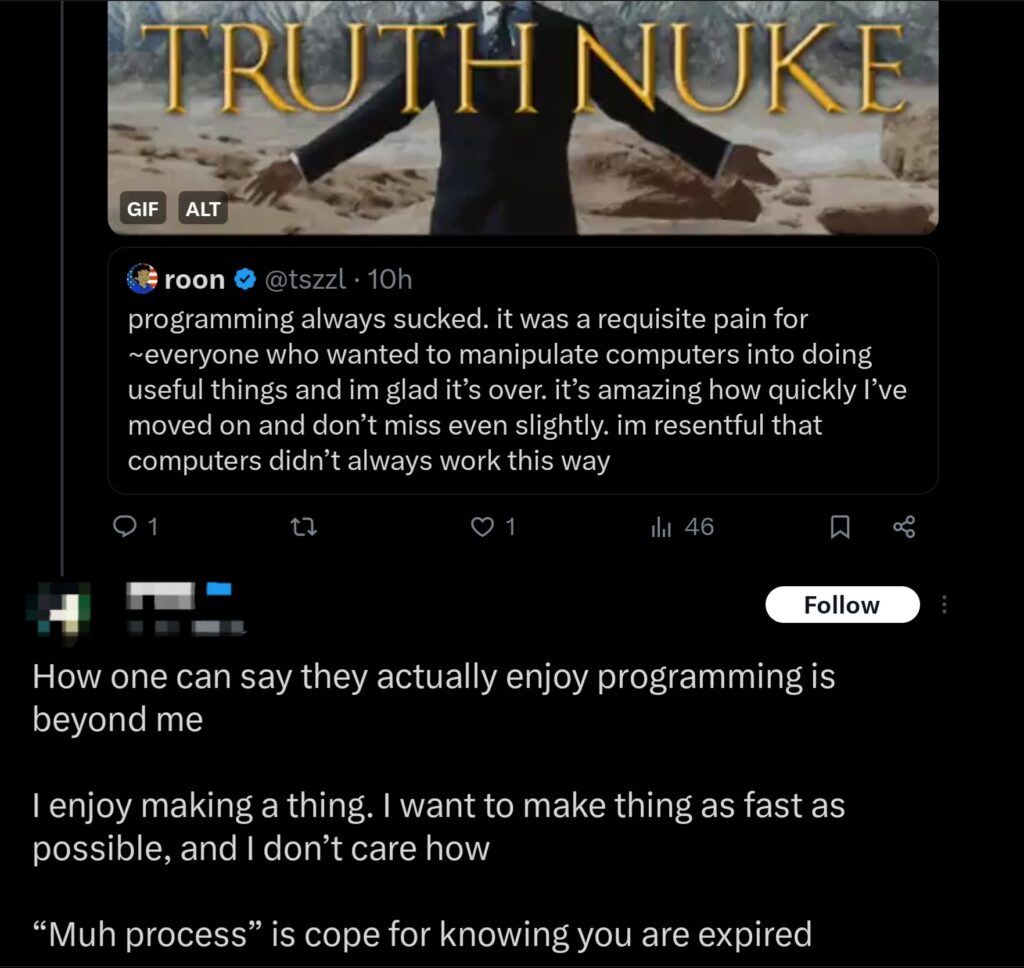
The sentiment isn’t entirely unanimous though:
In the past few years, the number of occasions in which I have vibe-coded is probably in the single digits. I’ve vibe-coded some helper Python scripts for my current project, Filemu, but everything within its main code-base is hand-written. I could probably be an order of magnitude more productive if I were to embrace LLM coding tools like Claude Code or Gemini Code Assist, but I have had virtually zero interest in doing so.
You see, I could not disagree any more with roon’s tweet. I really like programming! I like translating an algorithm into my head into lines of code, I like taking an idea for an app or a game and breaking it down into a formal systems architecture, I like thinking about the unique idiosyncrasies of computer architecture and working within those constraints, and I see zero appeal in delegating any of this work to an AI.
(I like writing too! None of this blog post, or any other post on my blog, is AI-generated.)
It’s evident however this is not a sentiment everyone shares; I might even be in the minority. It seems to me that there has been a sea change in the types of people that enter tech as a field of interest or as a career. This main distinction, I think, comes down to motivations.
Process vs Result
There are, in my view, two primary motivations (ignoring extrinsic motivations like money, fame, etc. for now) for choosing to create some sort of creative project: the enjoyment of the process, and the enjoyment of the result.
The process is the work necessary to manifest the final project. For a software the process is primarily programming – writing code in an IDE. For a painting the process is well, painting – applying viscous colored liquids to canvas.
Of course, not every aspect of the process needs to be enjoyed. Finagling programming language syntax is often annoying to me, for example (thus my use of LLMs for generating Python scripts, given that I don’t write Python very often and forget its syntax easily). Sometimes the process becomes simpler/easier and that can be welcome too. Printmaking used to involve carefully carving blocks of wood. Now we have linoleum – softer and more malleable than wood – as an alternative material. If enough of the process is enjoyable then the idea of delegating the process to an AI or to another person loses its appeal.
Frequently, the nature/subject domain of the process differs significantly from the nature/subject domain of the overall project and intended result. A videogame is largely an artistic work. Programming it is largely a technical one. Building an app is largely a technical work. Designing the logo and visual identity is largely an artistic one. It it thus somewhat understandable that one may find the process of a project unenjoyable.
Enjoyment of the result is self-explanatory. You’ve conceived of and imagined something in your mind’s eye, and now that idea has been made manifest. You’ve altered the state of various atoms in the universe to your will. That’s kinda cool, I guess!
Of course, people cannot be cleanly divided into two camps. Every individual, to some extent or another, enjoys the process. Every individual, to some extent or another, enjoys the result. Arguably, enjoyment of the result is a prerequisite motivation in the way that enjoyment of the process is not. Otherwise, there would be little desire to even conceive of and work on a project of any non-negligible level of complexity.
Sea Change
As technology has proliferated and become ever more ubiquitous through the decades, I think the motivations for people that enter tech have changed in subtle but important ways.
Becoming a programmer in the era of Jobs, Gates and Moore had a significant cognitive and motivational threshold. There was no Python or Javascript. Hardware was expensive and slow. Programming was far closer to the metal; a rich understanding of computer architecture was vital. This necessarily filters out people who a) did not have the capacity to develop a deep understanding of computer science or b) did not have the motivations to do so. In the age of blazing fast hardware, dynamically typed languages and garbage collection, this deep understanding is no longer necessary. Ease of access isn’t intrinsically a bad thing. More people should understand and contribute to the technology that we all use.
At the same time, ungodly amounts of wealth have entered the space, both wealth created within the space and wealth from outside the space hoping to create even more wealth. Extrinsic motivations begin to hold more power, and the desire to move fast and break things grows stronger.
I think we now have more people who enter technology who desire to become rich, to ‘change the world’ in some abstract sense or who just want some job security and they wish to accomplish all of this quickly and without the necessity of a strong understanding of technology or computer science.
More people in tech now enjoy the result and not the process.
Process Informs Result
This sea change, in principle, should not be a cause for concern. If there is more beautiful, useful and meaningful works in the world than we are all richer are we not?
The problem, however, is that process and result are inextricably linked – process informs result. The myriad of minor decisions one makes during the process of creation fundamentally affects the result. When one delegates the process to an AI, you are relinquishing these decisions to another, and in doing so, one can lose the understanding of the ramifications of these decisions.
My current project is an image-editing software, so it needs a way to load images from files and display them. Here’s a very broad overview of the workflow for loading an image in this software:
- Get the image format from the filename or from the file header.
- If the image is a camera RAW, ask user for import parameters then:
- Denoise the raw sensor data
- Correct the white balance
- Correct the exposure
- Demosaic to an RGB image
- If not, load the image normally. If the image has an embedded ICC profile, use the ICC profile to convert the image colorspace to sRGB.
- If the image is in grayscale or CMYK and does not have an ICC profile, manually convert it to sRGB.
- If the image has no alpha channel, initialize a fully opaque alpha channel.
- Convert the RGBA values to 32-bit float for the rendering engine.
- If the image is larger than the supported size, splice into tiles for the rendering engine to use.
- If the image has embedded EXIF data, import and parse the data. If the image was a camera RAW, take the partially parsed EXIF data from the library used to process the RAW and parse it further.
The final import flow is fairly complex, split over multiple functions, utilizing multiple libraries and capable of handling a variety of edge cases. It’s been revised and iterated on over multiple times throughout development to optimize for speed and memory usage. I’m not at all suggesting only a human could write this code. It’s totally possible for a current-gen LLM to produce similar code, but given the degrees of complexity and the interaction between different subsystems of the software and the different libraries used, it’ll quite likely require repeated iterations of prompting and multiple revisions, as was necessary when coding by hand.
This iterative process is fundamentally different when working with an LLM though. When revising and debugging your own code, you are interfacing with your own mental model of your code. Doing the same with an LLM means interfacing with the LLM’s ‘mental model’ instead, which is intrinsically far more opaque, not simply because it is another entity other than yourself, but also because LLMs are functionally black boxes from the perspective of the end user. This difference leads to several consequences.
Debugging your own code is debugging your own assumptions about your code. Debugging LLM-written code is debugging an LLM’s hallucinations.
The process of fixing code that you wrote is a process of disentangling your mental model of your code and the system it runs on from what is actually happening. When you fix these assumptions, you fix yourself. You correct your assumptions and thereby improve the alignment between your mental model of the computer and reality.
This does not occur to the same degree when debugging LLM code. When a human being inadvertently introduces a bug to their code, there’s frequently a logical reason it happens; a false assumption about the structure of a memory buffer; a misunderstanding of a library function. Why does the LLM introduce a given bug? The reasons frequently elude not just us, but the LLM itself. Little is learnt from correcting a hallucination – a stochastic error.
Coding is a series of tiny decisions. Tiny decisions that lead on to other tiny decisions, which add up slowly over time to have meaningful consequences.
How do you structure the flow of a function? How do you layout data in memory? How do you optimize the performance of a particular algorithm? Individually, these are small decisions and individually their consequences may be minor, but nevertheless they are decisions that should be made with awareness and understanding of the larger context. You could of course give said context to the LLM, either giving access to your entire codebase or with ever more elaborate prompts, but as the LLM shapes the codebase more than you do your mental model of your project can begin to diverge from reality. What does the project lack? Why does it perform poorly? Why does it use so much memory? You become dependent on the LLM to answer these questions for you and you must operate on the assumption that the LLM is answering accurately.
Revision and iteration is exploration.
When you are directly responsible for each line of code written, you have a granular understanding of how each line or each segment of code behaves. This is especially valuable for understanding speed and performance. In the slower process of revising and testing small changes you make, you see firsthand how each small change can improve or worsen performance. The application launch time just increased by 250ms? Oh, it happened when I added this function call. I instantly know who the culprit of this performance degradation is.
These individual concerns can broadly be summarized thus: I think a reliance on LLMs for programming reduces your ability to develop an accurate mental model of your program and the computer it runs on. You become more dependent on the LLM in a self-reinforcing feedback loop – an LLM that, in most cases, is owned and run by a for-profit corporation that ultimately does not answer to you and as we have seen with tech products and services elsewhere, enshittification is probably inevitable.
I think this effect has real practical consequences on the quality of software that we use. Having a strong understanding of our software and our computers is vital to making fast performant software! Consider this recent tweet from a developer working on Claude Code:
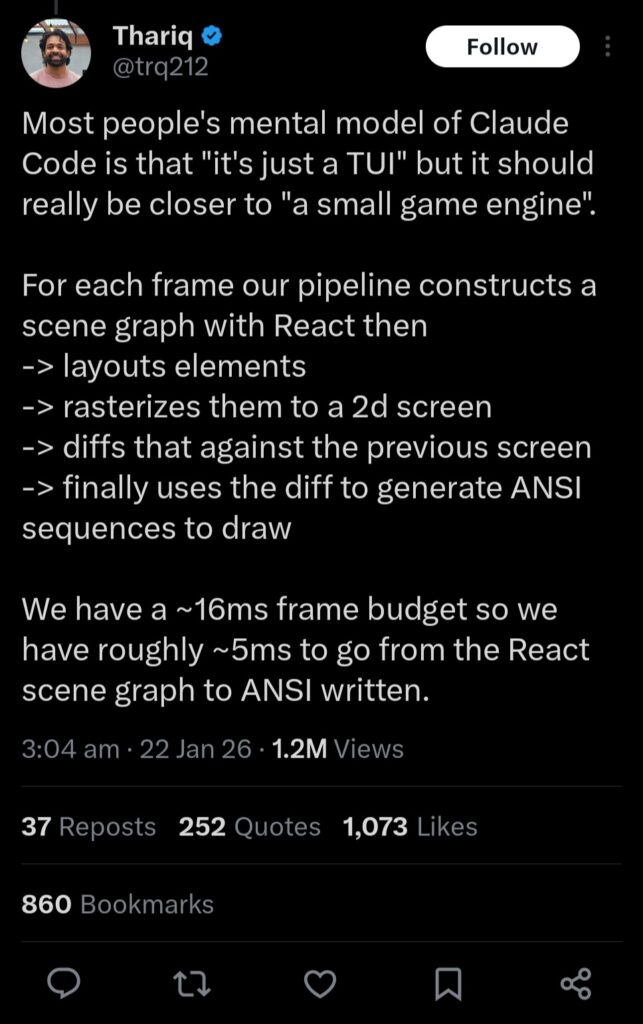
In this tweet, Thariq is effectively bragging that Claude Code’s terminal, the TUI (text-based user interface) in question, renders in at least 11ms, equating to a max framerate of about 90fps. For reference, this is what Claude Code’s terminal looks like:
The belief that rendering a small window’s worth of mono-spaced text within 11ms makes Claude Code similar to a ‘small game engine’ betrays a complete lack of understanding of the complexity of a ‘small game engine’ and the speed and capabilities of the underlying hardware our computers run on. Even the simplest of 2D videogames have to render – within the same frame budget – multiple animated images on screen, text of varying sizes and fonts, various shader effects and more; all done while also computing gameplay logic, physics and performing real-time playback of multiple audio files. If we lose the mental models of our own code and our hardware, we lose our capacity to understand just how much better and faster our software can be given the power of our computers.
Society has broadly recognized social media as easy to consume frictionless entertainment – so-called ‘brainrot’ – yet we rarely talk about vibe-coding in the same manner. We don’t perceive vibe-coding as brainrot as it preserves its veneer of value and professionalism under the guise of ‘productivity’, but continued use of it is degrading our understanding of our technology. Brainrot for work is still brainrot.